- Published on
Load 60 BERTs onto a single T4
- Written by
- Jonathan Ma, Kevin Lu
Say you’re an NLP researcher, and you have a bunch of different fine-tuned models you want to deploy, or you’re developing a customer service assistant, and each partner company requires a different model. If each model has a different, dynamic throughput, how will you serve them?
In this post, we will explain why dynamically colocating models on serverless GPUs is the best solution to the many-model dynamic-throughput problem. We demonstrate this feature’s power by dynamically loading 60 BERT models onto a single T4.

Naively, you can assign each model to a separate GPU. That’s clearly uneconomical - at the extreme, if you have 1000 models, each of which averages 1/1000 the throughput required to saturate a GPU, you’d spin up 1000 GPUs and waste 99.9% of your compute spend. A smarter approach would be to colocate some of the models on the same GPU. However, this does not handle usage spikiness – for example, two models might on average saturate only half of the GPU, but they may have concurrent peak throughputs that would individually demand a whole GPU.
This toy example illustrates a fundamental issue with cramming many different models onto the same GPU: predefining a fixed set of models to colocate on a GPU is inherently problematic because the throughput of models may vary over time. You’ll either have to leave some portion of the GPU unused most of the time to smoothly handle peak usage, or you will have to pack the GPU, overburdening it whenever there’s a usage spike, so that it is more optimally utilized for the majority of the time.
The solution is to dynamically colocate models without prespecifying which sets of models live on which GPUs beforehand. This is possible with an orchestrator that manages these GPUs in a serverless fashion and uses Dynamic Multiplexing, as the orchestrator can dynamically spin up GPUs at peak and migrate some inference tasks to them off of the increasingly overloaded existing GPUs.

We will illustrate dynamic colocation by using our ExaDeploy software to place 60 BERTs on a single Nvidia T4 GPU, without any foreknowledge of what these models actually are, so no assumptions are made about model architecture or weight sharing. In practice, the actual number will be handled and scaled by ExaDeploy because we do not prespecify a fixed set of models to colocate. If you have 60 models and the combined throughput is less than what is needed to saturate a single GPU, only a single GPU will be used. But, during a usage spike of any set of models, ExaDeploy can dynamically scale the GPU resources and migrate some subset of the throughput for those specific models to the new resources. In this way, ExaDeploy solves the heterogenous-model-colocation problem.
How will this fit in GPU memory?
If you load a single torchscripted BERT model into ExaDeploy and check the GPU memory consumption with NVIDIA SMI, you’ll see something like (1):
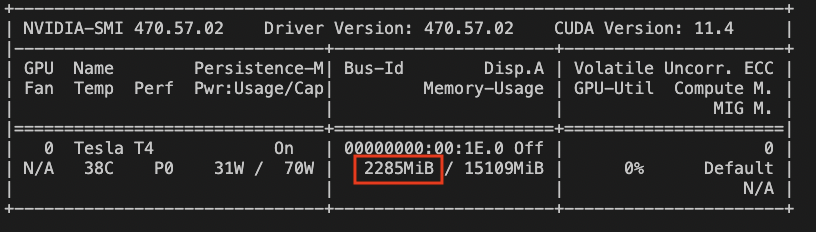
If a single BERT model takes up 2.3 GB of T4 GPU memory, how can we possibly fit 60 of them on a single T4? With these numbers, only 16 / 2.3 = ~6 of them can fit on a single GPU!
It turns out that the torchscripted BERT model itself, when using half-precision, only consumes around 200 MB of memory – a large chunk of the 2.3 GB is taken up by PyTorch itself, which can be shared across all of the models(2). Estimating ~12GB of non-PyTorch or other base plugin memory, we can get the claimed 12 / 0.2 = 60 models.
Issues with other frameworks
What’s preventing us from loading multiple models on the same GPU with other inference solutions on the market, like KServe or Seldon? Unfortunately, these services have multiple drawbacks when it comes to multi-model colocation:
- These frameworks will require you to prespecify the models you want to colocate together, which means that you’re subject to the same dilemma that we presented in the introduction of this post.
- Once you colocate two models together on these frameworks, they are no longer scaled independently – in other words, if you specify models A and B to colocate, and only B spikes in usage, both A and B will be loaded into the new resource that is spun up, even though A did not need additional resources.
- While ExaDeploy is deployed in Kubernetes clusters, it is easy to use and doesn’t require the customer to manage the Kubernetes cluster themselves.
ExaDeploy example
Let’s first register 100 BERT models in an ExaDeploy Module Repository:
# Upload TorchScript models to Module Repository.
with exa.ModuleRepository(
...
) as repo:
# For simplicity of example, we register 100 of the same model with different names.
# ExaDeploy makes no assumptions on these models’ similarity.
for i in range(100):
repo.register_torchscript(
f"BertGpu_{i}",
torchscript_file = torchscript_path,
input_names = ["input_ids", "attention_mask", "token_type_ids"],
output_names = ["output_tensor"],
plugin = "LibTorchPlugin:v1.12",
)
Next, let’s set up an ExaDeploy Session in a way that will dynamically load 60 of the 100 BERT models onto a single T4 (for details on the fields + API, check out the docs version of this blog post):
import random
# Run model on remote ExaDeploy runner.
# We choose a random subset of models for our sessions; this emphasizes that
# the models will be dynamically loaded.
module_idx_to_run = random.sample(range(100), 60)
# Store sessions in this list, forcing all 60 sessions to
# persist simultaneously.
sessions = []
for i in module_idx_to_run:
module_tag = f"BertGpu_{i}"
placement_group = exa.PlacementGroupSpec(
module_contexts = [
exa.ModuleContextSpec(module_tag = module_tag),
],
placement_group_affinity_key = "affinity-key-0",
max_placement_group_count = 60,
...
)
# Create a session, which will be loaded onto the runner.
sessions.append(exa.Session(
placement_groups = {"default": placement_group},
...
))
# run an inference.
The above code chooses 60 of our 100 BERTs at random (proving we don’t need to prespecify a fixed set of models) and loads them onto a single runner (which maps to a single T4 resource). kubectl should confirm that all of this has been accomplished using just 1 runner:
> kubectl get pods
NAME READY STATUS RESTARTS AGE
runner-00747134261729369700 1/1 Running 0 3m
While not demonstrated, if one of these models gets a usage spike, ExaDeploy will scale it up independently of the other models, unlike other inference-serving solutions.
We can again use NVIDIA SMI to check GPU utilization of the runner with this new code:
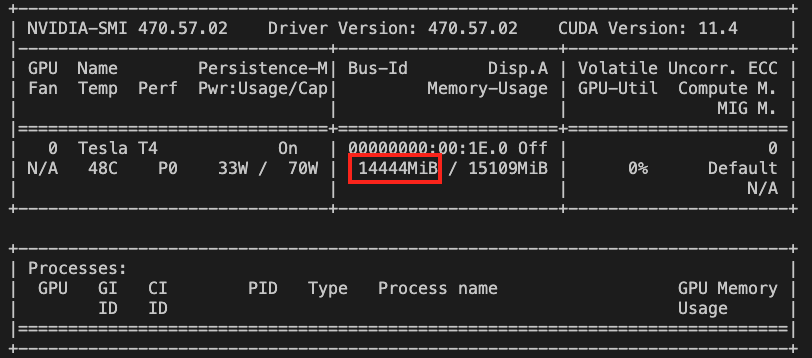
Much more saturation!
Conclusion
We’ve demonstrated that ExaDeploy allows you to colocate heterogeneous models together without prespecifying them beforehand. This has numerous applications to real-world settings where a user may want to colocate many rarely-used models together onto a single GPU, but does not want the burden of defining sets of models that can be safely packed together or building autoscaling mechanisms to handle spiky usage patterns.
Join our community Slack to stay in the loop and learn more about ExaDeploy!
(1) You may have noticed that the total available GPU memory in the NVIDIA SMI screenshots above is 15.1 GB, rather than the 16 GB advertised for a T4. Curious why this is the case? Check out our blog post to learn how you can access the full 16GB of memory with one simple trick.
(2) While we do not assume anything about model frameworks when it comes to dynamic colocation, if you have many models across multiple frameworks, it is better to place models of the same framework in the same “group” of models that could be potentially colocated because of this per-framework memory overhead.