- Published on
Are GPUs Worth it for ML?
- Written by
- Exafunction Team
In theory, this sounds like a dumb question. Machine Learning models, particularly Deep Learning models, are (mostly) a bunch of arithmetic operations, especially parallelizable ones like matrix multiplications. GPUs, by design, are optimized for parallelizable arithmetic operations. It's a match made in heaven.
Source: NVIDIA (2019)
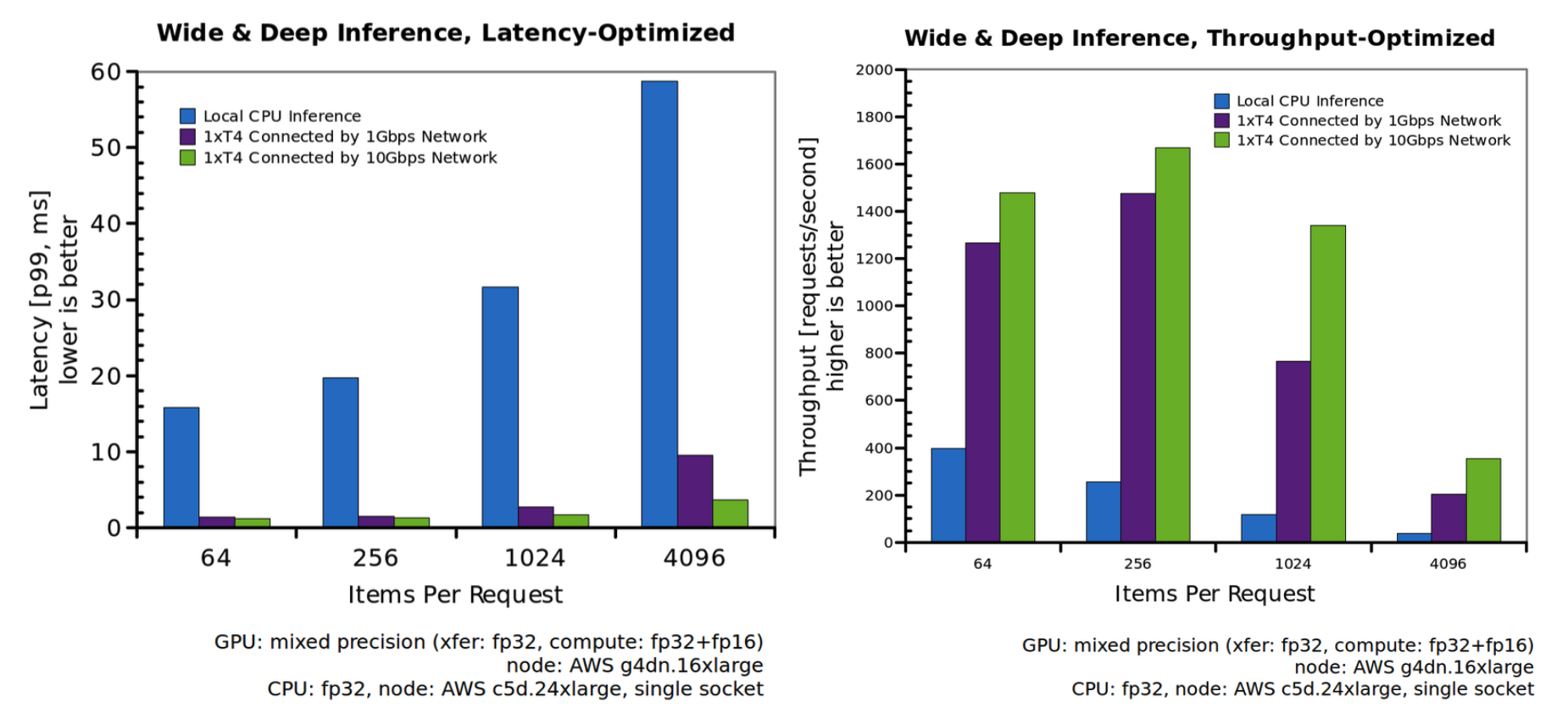
But just like most things that sound great in theory, the story is different in practice. In reality, we almost always have to do some preprocessing of inputs and postprocessing of outputs on either end of an ML inference, or some other operations that aren't GPU-optimized. Ok, you might say, I'll just run those stages on a CPU and run the inference on a GPU - best of both worlds!(1)
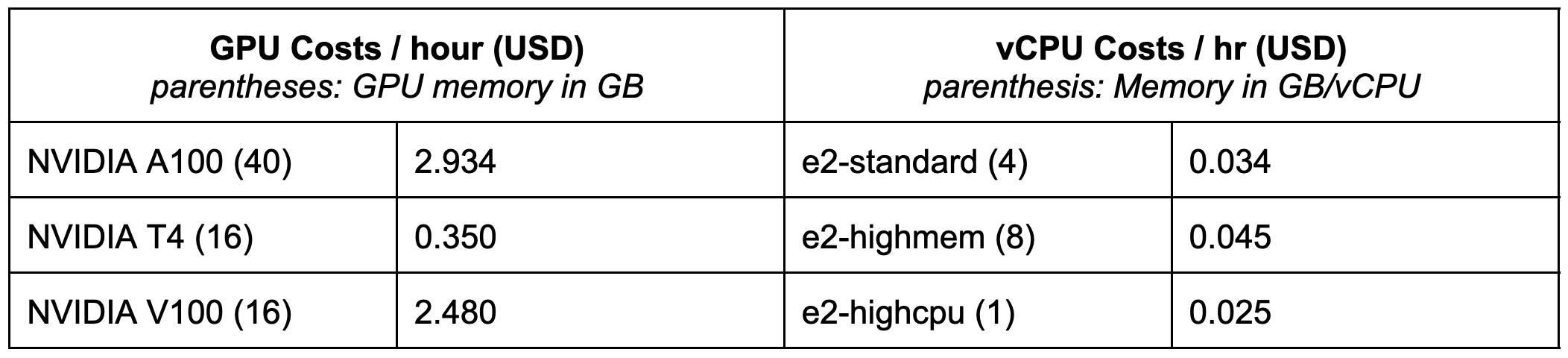
Unfortunately, these computations are often more time consuming and intensive than the inference itself. And CPUs are so much cheaper. It feels wasteful to have an expensive GPU sitting idle while we are executing the CPU portions of the ML workflow. Sure, latency is nice, but is the cost really worth it? Using the statistics from NVIDIA, should we just eat a 7x slowdown on the inference stage and run everything on CPU?
Source: GCP (2022)
As shown above, GPU instances are an order of magnitude more expensive than that of CPUs, with similar results across cloud providers. And we haven't even mentioned the scarcity problem of GPUs.
So in reality, there are two camps:
- Latency Conscious: Pay for both the CPU and GPU to get the quickest request turnaround.
- Cost Conscious: Take a hit on latency by running the ML model inference on CPU to get cheaper cost.

This is not the end of the story though because of one big aspect of most ML workloads - lots of concurrent requests(2). Modern batch ML workloads operate at much higher scale than a single inference at a time, and so with a little systems magic, neither of these two camps should have to sacrifice on cost or latency. The basic premise is that a bunch of "clients" can do their CPU computation on their own dedicated CPUs and do any GPU-optimized computation (i.e. model inference) on a shared GPU resource. Of course we don't have a preset schedule of requests, so all of this GPU resource sharing has to be done dynamically. Borrowing some terminology from the networking world, we refer to this approach as "dynamic multiplexing."
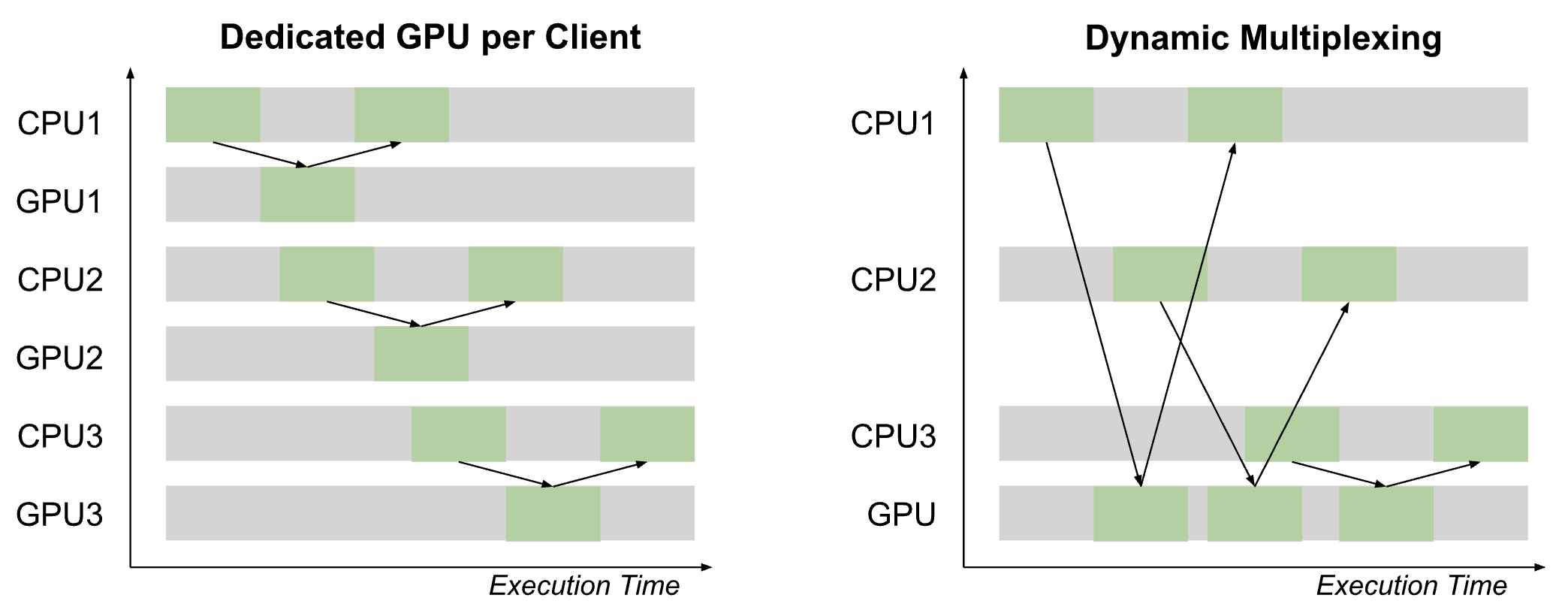
Let's make this more concrete with some numbers. Say we have a workload where, per "request," we need 90ms of CPU-only preprocess/postprocess and a model inference that would take 10ms on a GPU and 210ms on a CPU. Let's say we have 10 clients that each make a request every 100ms. Finally, let's say each CPU costs 1 unit and each GPU costs 5 units (per some standardized time interval). How does each option shape up?
- Latency Conscious (dedicated GPU per client): Each request from each client can be satisfied with 1 CPU and 1 GPU per client, with an optimal latency of 100ms and cost of 10 * (1 + 5) = 60 units.
- Cost Conscious (CPU only): Since each call will have latency of 300ms, we will need 3 CPUs per client to satisfy all requests. Even though we took a hit on latency, the cost is now just 10 * 3 = 30 units.
- Dynamic Multiplexing (shared GPU): With 10 clients, a call from each every 100ms, and 10ms of GPU time required per call, we can fully satisfy all calls with a single shared GPU resource!(3) Each client still needs a dedicated CPU, but we now have optimal 100ms latency per call and a cost of only 10 * 1 + 5 = 15 units.
Dynamic multiplexing lets us have our cake and eat it too!(4)
Clearly this was a toy example, and dynamic multiplexing hosts its own set of challenges:
- Too few clients to a GPU resource and you are underutilizing it, but too many clients to a GPU resource and you start introducing a minimum "wait latency" when clients are blocked on another client's inference.
- Some models don't batch well, such as language models with variable input sequence lengths.
- Preprocessing times and model inference times may not be constant, either due to randomness or programmed to change over the course of the batch workload.
- The shape of CPU/GPU resources needed may not match the available colocated nodes.
We'll discuss in the future how we've solved these challenges and how we've taken dynamic multiplexing even further, such as executing multiple models on a GPU at the same time if the models have poor GPU utilization when running (ex. long kernel load times).
As discussed in our earlier post, we at Exafunction want to remove all pains and concerns that ML practitioners feel when deploying their workloads. Cost and latency arguably top that list, so we knew that we needed to solve this dynamic multiplexing problem with ExaDeploy. For numbers, we have successfully been able to multiplex 30 clients to a single GPU for our customers' workloads, a big reason why some of their GPU costs have dropped by ~97% by using ExaDeploy.
This all being said, there are even more things we can do to keep squeezing out cents and milliseconds, and we will explore these in future blog posts(5). But just with dynamic multiplexing, we can answer this post's motivating question: yes, GPUs are absolutely worth it if utilized properly!
If you are currently weighing this cost vs latency tradeoff for your ML workloads, we want to chat with you - send us a message here!
(1) We will assume zero cost and latency data passing between CPU and GPU, and that orchestration of this data passing is trivial. Also, we assume that there are no headaches in managing multiple resource types. All of this is obviously not true, but we will get more into the effects of network data passing and how that changes the calculus in a future blog post!
(2) Another workload pattern is the inverse: instead of just a few models each with extremely high throughput, there are many different fine tuned models, each with less throughput. One application where this is common is the NLP space, where we might have many fine-tuned models (many sets of weights for the same model architecture) for different applications. While we talk in this blog post about how to address latency vs cost for the few model/high throughput case, we will talk about this inverse in a future blog post!
(3) Obviously this will require the calls to come in a perfect stagger, but entertain us for this toy example :)
(4) In this example, it came out cheaper to do dynamic multiplexing rather than CPUs only, but it isn't too difficult to find a set of input parameters where this isn't the case. That being said, in practice, we have noticed the costs from dynamic multiplexing to be less than or comparable to doing CPUs only (a far cry from the order-of-magnitude more from dedicated GPU resources), and the latency wins almost always make it worth the occasional slight increases in cost.
(5) We will keep focusing on what can be done on the software level. Of course, there are hardware-based advances, such as hardware accelerators like Amazon's Inferentia, and we are excited to explore how to make our software interface with these advances to create the best possible overall solutions for your use cases.