- Published on
Getting Rid of CPU-GPU Copies in TensorFlow
- Written by
- Douglas Chen
At Exafunction, we’re constantly searching for ways to make GPUs more efficient. This article is part of our series on GPU Tips and Tricks, where we’ll share interesting insights and learnings we found along the way. Stay tuned for more content about how you can get the most out of your GPU in deep learning applications!
GPUs are the most cost-effective way to get low-latency deep learning inference serving in the cloud. One of the major bottlenecks when using GPUs is copying data between the CPU and GPU memory over the PCIe bus. For many deep learning models intended for high-resolution image and video processing, simply copying the inputs can significantly increase the overall latency of the system, especially when non-inference tasks like decompression and preprocessing can also be executed and chained on the GPU.
In this blog post, we'll show how to pass model inputs and outputs directly through GPU memory for model inferences in TensorFlow, bypassing the PCIe bus and CPU memory entirely.
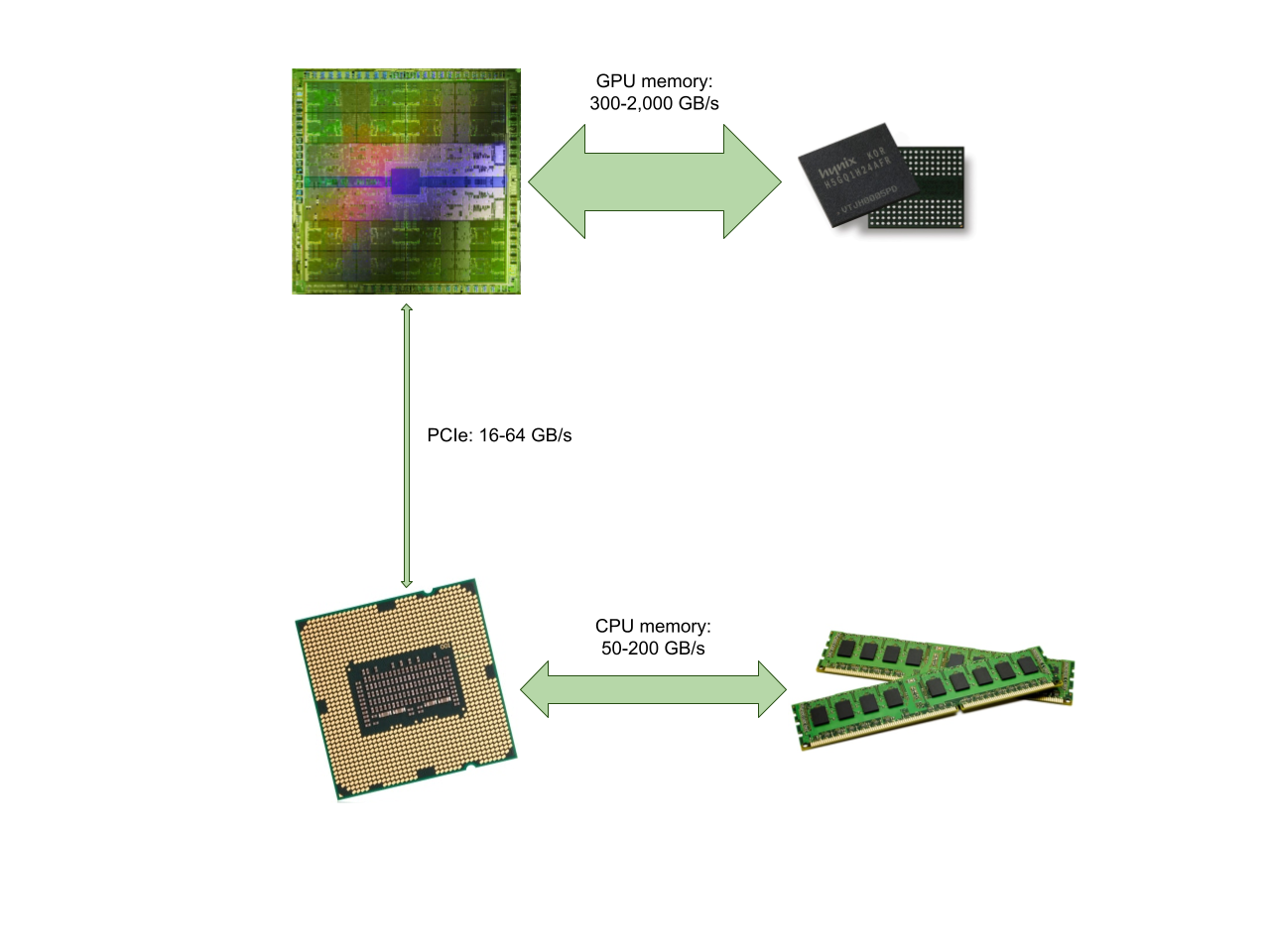
As most GPU code is written in CUDA, we'll use TensorFlow's C++ interfaces to demonstrate this technique. This is most useful to interface with other libraries such as OpenCV for GPU-accelerated image preprocessing and NVIDIA NVDEC for hardware-accelerated video decoding.
Initial Setup
In TensorFlow's C++ interface, tensorflow::LoadSavedModel is used to load a model bundle:
tensorflow::SavedModelBundle bundle;
TF_RETURN_IF_ERROR(bundle, tensorflow::LoadSavedModel(
session_options, run_options, saved_model_dir, tags, &bundle
));
The model bundle can then be run using the tensorflow::Session. By default, this uses the CPU:
tensorflow::Session* session = bundle.GetSession();
// Create a tensor in CPU memory
tensorflow::Tensor tensor(tensorflow::DT_FLOAT, {1, 2, 3});
// Pairs of feed name and tensor to pass into the model
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs{"input", std::move(tensor)};
// The outputs will be written here. These will also be on the CPU.
std::vector<tensorflow::Tensor> outputs;
// Tensor names to fetch for the output.
std::vector<std::string> fetch_names;
// Run the model!
session->Run(inputs, fetch_names, {}, &outputs);
Using the GPU
Using the GPU is a bit more involved. First, a tensorflow::CallableOptions must be created from the session to specify which tensors are passed into and out of GPU memory instead of CPU memory. Also, it is necessary to specify which GPU the memory will be fed and fetched from. For simplicity in this example we will place all input and output tensors onto the first GPU:
tensorflow::CallableOptions callable_options;
std::string gpu_device_name = FirstGpuDeviceName(session);
// Names of input tensors.
std::vector<std::string> feed_names;
*callable_options.mutable_feed() = {feed_names.begin(), feed_names.end()};
// Names of output tensors.
std::vector<std::string> fetch_names;
*callable_options.mutable_fetch() = {fetch_names.begin(), fetch_names.end()};
auto& feed_devices = *callable_options.mutable_feed_devices();
for (auto& input_name : feed_names) {
feed_devices[input_name] = gpu_device_name;
}
auto& fetch_devices = *callable_options.mutable_fetch_devices();
for (auto& output_name : fetch_names) {
fetch_devices[output_name] = gpu_device_name;
}
Note that to get the first GPU device name, we use the following helper function:
std::string FirstGpuDeviceName(tensorflow::Session* session) {
// Gets device name for the first GPU in the session.
std::vector<tensorflow::DeviceAttributes> devices;
auto status = session->ListDevices(&devices);
assert(status.ok());
for (const tensorflow::DeviceAttributes& d : devices) {
if (d.device_type() == "GPU" || d.device_type() == "gpu") {
return d.name();
}
}
CHECK(false) << "GPU not found";
}
Now, we can create a tensorflow::Session::CallableHandle that encapsulates how to run the TensorFlow graph with the inputs and outputs on the GPU. Creating and destroying the callable is expensive, so this should only be done once at model initialization time. Also, the callable should be destroyed before the session itself is destroyed.
TF_RETURN_IF_ERROR(session->MakeCallable(callable_options, &callable));
// Before the session is destroyed:
// session->ReleaseCallable(callable);
Finally, we need to create some input tensors. In this example we will just use TensorFlow's built-in GPU allocator, but it is possible to also pass in external GPU buffers via the tensorflow::TensorBuffer interface.
// Get TensorFlow's GPU allocator for device 0
// This needs to match the device placement used when loading the SavedModel
// and creating the session.
tensorflow::TfDeviceId gpu_device_id(0);
tensorflow::Allocator* gpu_allocator =
tensorflow::GPUProcessState::singleton()->GetGPUAllocator(gpu_device_id);
// Synchronize to ensure memory can be safely allocated & overwritten
cudaDeviceSynchronize();
// The input tensors are now allocated in GPU memory using TensorFlow's
// allocator. They must be in the same order as the feed names.
std::vector<tensorflow::Tensor> inputs;
for (int i = 0; i < 10; i++) {
tensorflow::Tensor tensor(gpu_allocator, tensorflow::DT_FLOAT, {1, 2, 3});
// Fill the input here
inputs.push_back(std::move(tensor));
}
// Synchronize to ensure the inputs are valid
cudaDeviceSynchronize();
Finally, we can run the model. Now TensorFlow will both use the inputs directly from the GPU and also place the outputs on the same GPU!
// The outputs will also be placed on the GPU thanks to the fetch_devices
// setting above.
std::vector<tensorflow::Tensor> outputs;
TF_RETURN_IF_ERROR(session->RunCallable(callable, inputs, &outputs, nullptr));
We have a more complete code sample in the Appendix.
With CUDA streams
You may now be wondering how this interacts with CUDA streams. Even though TensorFlow internally uses CUDA streams, the above example is synchronous. We have to run cudaDeviceSynchronize before allocating memory to ensure that we don't corrupt previously allocated TensorFlow memory. We also have to synchronize after writing the inputs to ensure that TensorFlow sees valid inputs. TensorFlow itself also synchronizes the GPU at the end of the model execution to ensure that the output tensors are valid.
Clearly, this is not ideal in situations where we want the GPU to run asynchronously for as long as possible to minimize blocking caused by the CPU. Fortunately, we can access the internal TensorFlow CUDA stream. The inputs must be synchronized with respect to TensorFlow's stream, and users of the outputs must synchronize with TensorFlow's stream before accessing the memory. Using this stream allows us to do away entirely with the synchronizations.
First, we set an extra option on the CallableOptions to disable TensorFlow's internal synchronization at the end of the model execution:
callable_options.set_fetch_skip_sync(true);
We can access the internal stream using the following helper function, which also takes the device name:
cudaStream_t stream = GetTfGpuStream(session, gpu_device_name);
// Returns the tensorflow::BaseGPUDevice for a given device name
tensorflow::BaseGPUDevice* GetTfGpuDevice(tensorflow::Session* session,
const std::string& gpu_device_name) {
const tensorflow::DeviceMgr* device_mgr;
auto status = session->LocalDeviceManager(&device_mgr);
CHECK(status.ok()) << status;
tensorflow::Device* device;
status = device_mgr->LookupDevice(gpu_device_name, &device);
CHECK(status.ok()) << status;
auto* gpu_device = dynamic_cast<tensorflow::BaseGPUDevice*>(device);
return CHECK_NOTNULL(gpu_device);
}
// Returns the compute stream for a given TensorFlow GPU device.
cudaStream_t GetTfGpuStream(tensorflow::Session* session,
const std::string& gpu_device_name) {
auto* device = GetTfGpuDevice(session, gpu_device_name);
const tensorflow::DeviceBase::GpuDeviceInfo* device_info =
device->tensorflow_gpu_device_info();
CHECK_NOTNULL(device_info);
CUstream tf_stream =
stream_executor::gpu::AsGpuStreamValue(device_info->stream);
return tf_stream;
}
Creating the model inputs and running it now looks like this. Note the lack of calls to cudaDeviceSynchronize!
cudaStream_t stream = GetTfGpuStream(session, gpu_device_name);
std::vector<tensorflow::Tensor> inputs;
for (int i = 0; i < 10; i++) {
tensorflow::Tensor tensor(gpu_allocator, tensorflow::DT_FLOAT, {1, 2, 3});
// Fill input buffers here, using the stream in kernel calls
// or calls to cudaMemcpyAsync. Alternatively, synchronize with another
// GPU stream using events.
inputs.push_back(std::move(tensor));
}
std::vector<tensorflow::Tensor> outputs;
TF_RETURN_IF_ERROR(session->RunCallable(callable, inputs, &outputs, nullptr));
cudaStreamSynchronize(stream);
Note that GPU synchronizations might still happen while running the model if TensorFlow internally needs to copy memory from the GPU to CPU. However, there are no longer any synchronizations inherently required as part of passing inputs and outputs to the model.
As with the previous section, a more complete code sample is in the Appendix.
Conclusion
In this post, we've demonstrated how to pass inputs and outputs to and from TensorFlow entirely on the GPU, bypassing overhead from the PCIe bus and limited CPU memory bandwidth. At Exafunction, we use techniques like this in our model serving solution, ExaDeploy, to maximize GPU utilization even for models that have extremely large inputs and outputs.
Join our community Slack to stay in the loop with these cost and latency saving tips!
Appendix
A more complete code example for the concepts described above is shown below.
#include <cuda_runtime.h>
#define GOOGLE_CUDA 1
#include "tensorflow/cc/saved_model/loader.h"
#include "tensorflow/core/common_runtime/device.h"
#include "tensorflow/core/common_runtime/device_mgr.h"
#include "tensorflow/core/common_runtime/gpu/gpu_device.h" // requires GOOGLE_CUDA
#include "tensorflow/core/common_runtime/gpu/gpu_process_state.h"
#include "tensorflow/core/framework/tensor.h"
#include "tensorflow/core/platform/stream_executor.h"
#include "tensorflow/core/protobuf/config.pb.h"
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/public/version.h"
#include "tensorflow/core/util/device_name_utils.h"
#include "tensorflow/stream_executor/gpu/gpu_stream.h"
tensorflow::Status LoadSavedModel(
const std::string& saved_model_dir,
tensorflow::SavedModelBundle* bundle
) {
// Load the SavedModel and create a Session
tensorflow::SessionOptions session_options;
tensorflow::RunOptions run_options;
std::unordered_set<std::string> tags{"serve"};
// Can also use SavedModelBundleLite if the metagraph is not needed
return tensorflow::LoadSavedModel(
session_options,
run_options,
saved_model_dir,
tags,
bundle
);
}
tensorflow::Status LoadAndRunCpu() {
const std::string& saved_model_dir = "your_saved_model";
tensorflow::SavedModelBundle bundle;
TF_RETURN_IF_ERROR(LoadSavedModel(saved_model_dir, &bundle));
// Use the Session to run the model.
tensorflow::Session* session = bundle.GetSession();
// {feed_name, tensor} pairs for the input.
// The tensors are be allocated in CPU memory.
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs;
for (int i = 0; i < 10; i++) {
tensorflow::Tensor tensor(tensorflow::DT_FLOAT, {1, 2, 3});
inputs.push_back({"input_" + std::to_string(i), std::move(tensor)});
}
// The outputs will be written here. The tensors will also be allocated in CPU
// memory.
std::vector<tensorflow::Tensor> outputs;
// Tensor names to fetch for the output.
std::vector<std::string> fetch_names;
// Call session->Run to run the model.
return session->Run(inputs, fetch_names, {}, &outputs);
}
std::string FirstGpuDeviceName(tensorflow::Session* session) {
// Gets device name for the first GPU in the session.
std::vector<tensorflow::DeviceAttributes> devices;
auto status = session->ListDevices(&devices);
assert(status.ok());
for (const tensorflow::DeviceAttributes& d : devices) {
if (d.device_type() == "GPU" || d.device_type() == "gpu") {
return d.name();
}
}
return "";
}
tensorflow::Status LoadAndRunGpu() {
const std::string& saved_model_dir = "your_saved_model";
tensorflow::SavedModelBundle bundle;
TF_RETURN_IF_ERROR(LoadSavedModel(saved_model_dir, &bundle));
// Use the Session to run the model
tensorflow::Session* session = bundle.GetSession();
// Create a Callable. Like the Session, this should be reused across calls
// to the same model.
// The Callable gives us more options when running the TensorFlow Graph,
// including the option to pass inputs and outputs from GPU devices rather
// than the CPU.
tensorflow::Session::CallableHandle callable;
tensorflow::CallableOptions callable_options;
// We need the device name of the GPU to set up the Callable.
std::string gpu_device_name = FirstGpuDeviceName(session);
// Names of input tensors.
std::vector<std::string> feed_names;
*callable_options.mutable_feed() = {feed_names.begin(), feed_names.end()};
// Names of output tensors.
std::vector<std::string> fetch_names;
*callable_options.mutable_fetch() = {fetch_names.begin(), fetch_names.end()};
// Set up the Callable to use the GPU for all inputs and outputs.
auto& feed_devices = *callable_options.mutable_feed_devices();
for (auto& input_name : feed_names) {
feed_devices[input_name] = gpu_device_name;
}
auto& fetch_devices = *callable_options.mutable_fetch_devices();
for (auto& output_name : fetch_names) {
fetch_devices[output_name] = gpu_device_name;
}
// Create the callable.
TF_RETURN_IF_ERROR(session->MakeCallable(callable_options, &callable));
// Get TensorFlow's GPU allocator for device 0
// This needs to match the device placement used when loading the SavedModel
// and creating the session.
tensorflow::TfDeviceId gpu_device_id(0);
tensorflow::Allocator* gpu_allocator =
tensorflow::GPUProcessState::singleton()->GetGPUAllocator(gpu_device_id);
// Synchronize to ensure memory can be safely allocated / overwritten
cudaDeviceSynchronize();
// The input tensors are now allocated in GPU memory using TensorFlow's
// allocator. They must be in the same order as the feed names.
std::vector<tensorflow::Tensor> inputs;
for (int i = 0; i < 10; i++) {
tensorflow::Tensor tensor(gpu_allocator, tensorflow::DT_FLOAT, {1, 2, 3});
inputs.push_back(std::move(tensor));
}
// Synchronize to ensure the inputs are valid
cudaDeviceSynchronize();
// The outputs will also be placed on the GPU thanks to the fetch_devices
// setting above.
std::vector<tensorflow::Tensor> outputs;
// Call session->RunCallable to run the model.
TF_RETURN_IF_ERROR(session->RunCallable(callable, inputs, &outputs, nullptr));
// Release the Callable after you're done with it, before the session itself
// is destroyed
return session->ReleaseCallable(callable);
}
// Returns the tensorflow::BaseGPUDevice for a given device name
tensorflow::BaseGPUDevice* GetTfGpuDevice(tensorflow::Session* session,
const std::string& gpu_device_name) {
const tensorflow::DeviceMgr* device_mgr;
auto status = session->LocalDeviceManager(&device_mgr);
CHECK(status.ok()) << status;
tensorflow::Device* device;
status = device_mgr->LookupDevice(gpu_device_name, &device);
CHECK(status.ok()) << status;
auto* gpu_device = dynamic_cast<tensorflow::BaseGPUDevice*>(device);
return CHECK_NOTNULL(gpu_device);
}
// Returns the compute stream for a given TensorFlow GPU device.
cudaStream_t GetTfGpuStream(tensorflow::Session* session,
const std::string& gpu_device_name) {
auto* device = GetTfGpuDevice(session, gpu_device_name);
const tensorflow::DeviceBase::GpuDeviceInfo* device_info =
device->tensorflow_gpu_device_info();
CHECK_NOTNULL(device_info);
CUstream tf_stream =
stream_executor::gpu::AsGpuStreamValue(device_info->stream);
return tf_stream;
}
tensorflow::Status LoadAndRunGpuAsync() {
const std::string& saved_model_dir = "your_saved_model";
tensorflow::SavedModelBundle bundle;
TF_RETURN_IF_ERROR(LoadSavedModel(saved_model_dir, &bundle));
// Use the Session to run the model
tensorflow::Session* session = bundle.GetSession();
// Create a Callable. Like the Session, this should be reused across calls
// to the same model.
// The Callable gives us more options when running the TensorFlow Graph,
// including the option to pass inputs and outputs from GPU devices rather
// than the CPU.
tensorflow::Session::CallableHandle callable;
tensorflow::CallableOptions callable_options;
// We need the device name of the GPU to set up the Callable.
std::string gpu_device_name = FirstGpuDeviceName(session);
// Names of input tensors.
std::vector<std::string> feed_names;
*callable_options.mutable_feed() = {feed_names.begin(), feed_names.end()};
// Names of output tensors.
std::vector<std::string> fetch_names;
*callable_options.mutable_fetch() = {fetch_names.begin(), fetch_names.end()};
// Set up the Callable to use the GPU for all inputs and outputs.
auto& feed_devices = *callable_options.mutable_feed_devices();
for (auto& input_name : feed_names) {
feed_devices[input_name] = gpu_device_name;
}
auto& fetch_devices = *callable_options.mutable_fetch_devices();
for (auto& output_name : fetch_names) {
fetch_devices[output_name] = gpu_device_name;
}
// Set to disable synchronization at the end of the model.
callable_options.set_fetch_skip_sync(true);
// Create the callable.
TF_RETURN_IF_ERROR(session->MakeCallable(callable_options, &callable));
// Get TensorFlow's GPU allocator for device 0
// This needs to match the device placement used when loading the SavedModel
// and creating the session.
tensorflow::TfDeviceId gpu_device_id(0);
tensorflow::Allocator* gpu_allocator =
tensorflow::GPUProcessState::singleton()->GetGPUAllocator(gpu_device_id);
// The input tensors are now allocated in GPU memory using TensorFlow's
// allocator. They must be in the same order as the feed names.
std::vector<tensorflow::Tensor> inputs;
for (int i = 0; i < 10; i++) {
tensorflow::Tensor tensor(gpu_allocator, tensorflow::DT_FLOAT, {1, 2, 3});
inputs.push_back(std::move(tensor));
}
// The outputs will also be placed on the GPU thanks to the fetch_devices
// setting above.
std::vector<tensorflow::Tensor> outputs;
// Call session->RunCallable to run the model.
TF_RETURN_IF_ERROR(session->RunCallable(callable, inputs, &outputs, nullptr));
// Manually synchronize against TensorFlow's stream
cudaStream_t stream = GetTfGpuStream(session, gpu_device_name);
cudaStreamSynchronize(stream);
// Outputs are valid now
// Release the Callable after you're done with it, before the session itself
// is destroyed
return session->ReleaseCallable(callable);
}
int main() {
LoadAndRunCpu();
LoadAndRunGpu();
LoadAndRunGpuAsync();
}